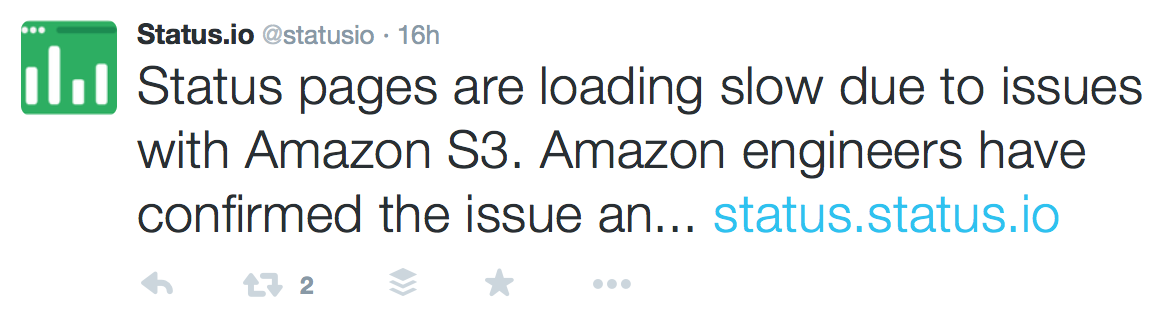
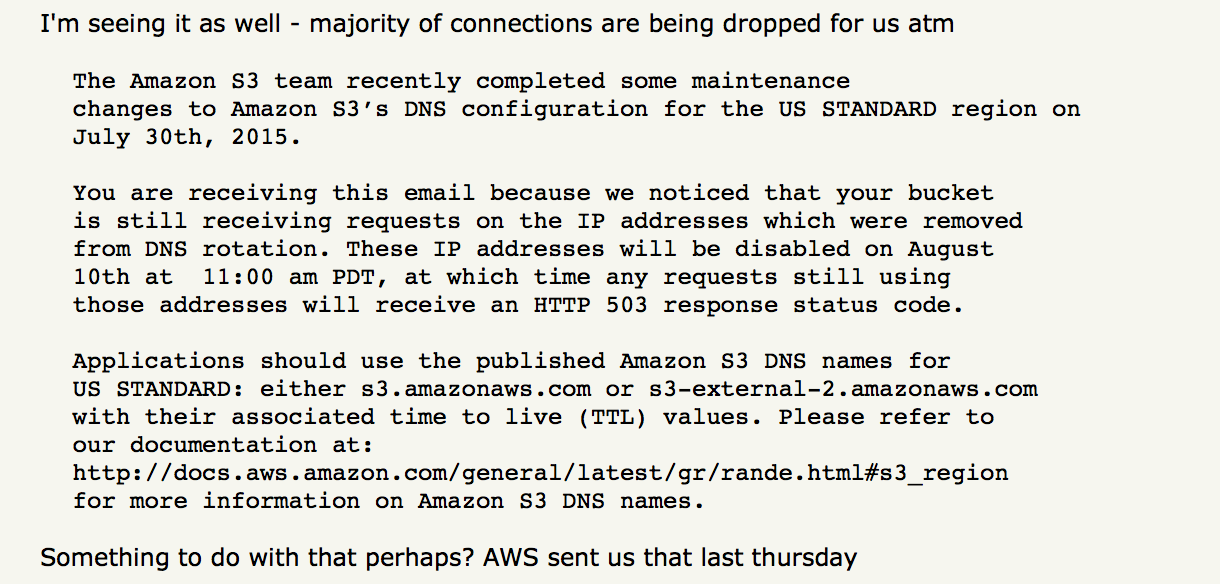
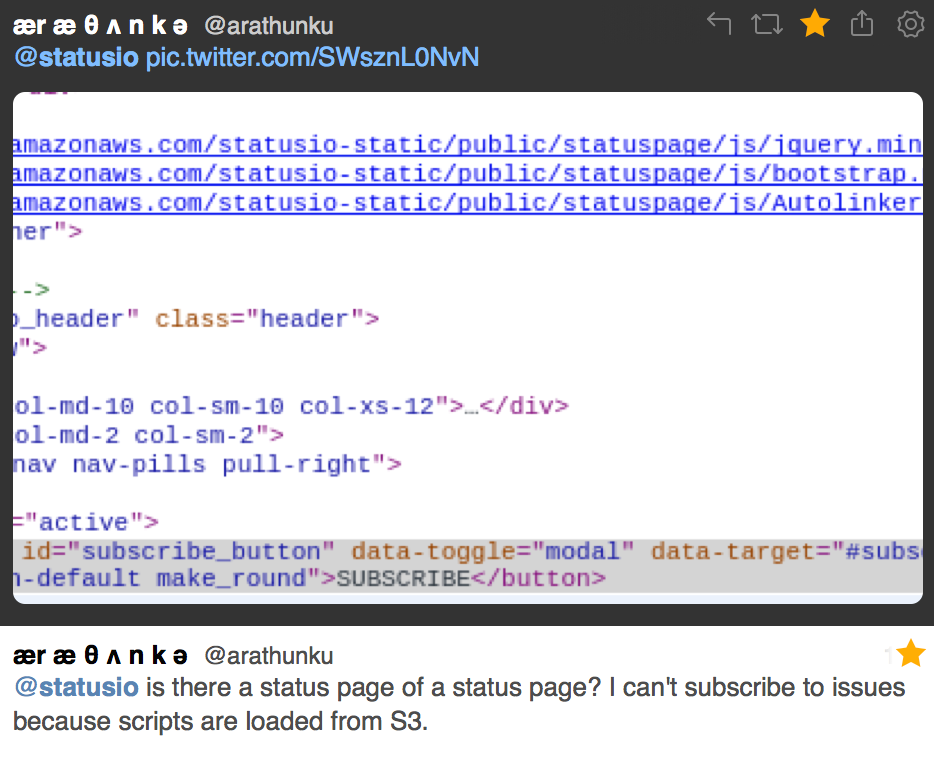
Incidents with severe impact usually deserve a public postmortem report. The best way to restore trust and delight your users is with an authentic, detailed postmortem report.
While some organizations add postmortems to their status pages, we found that most are using their primary company blog.
We made it simple to link directly to these external postmortems from within an incident. Learn more
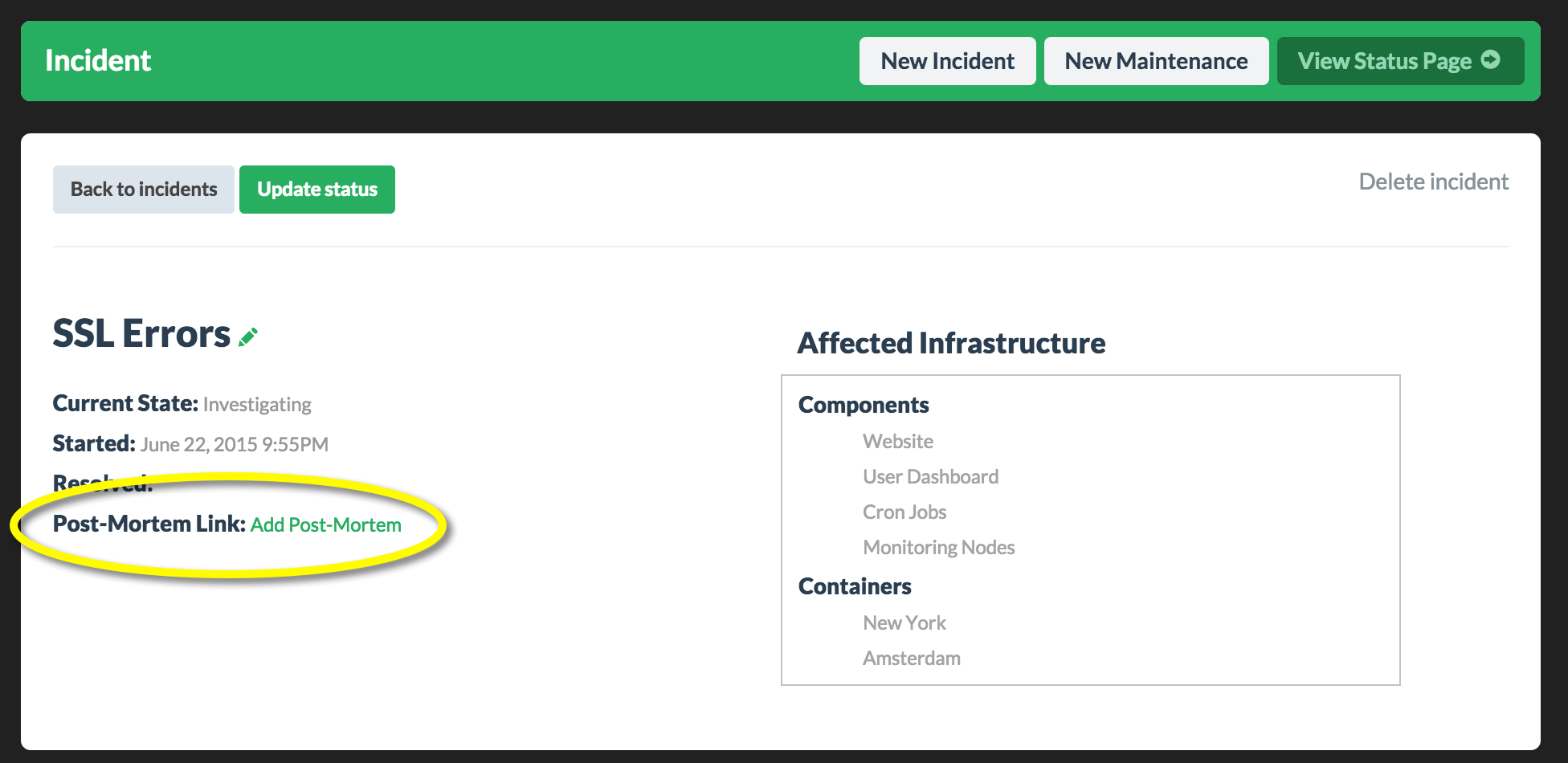
There is no standard when it comes to writing a postmortem report. Basically, just be authentic and describe what happened, what was impacted, and what steps were taken to prevent this from reoccurring in the future.
We’ve compiled some resources to help you get started crafting postmortem reports that will delight your users. Below are a ton of examples of actual postmortems from some of the most popular services on the internet.
Example Postmortem Reports
Amazon Web Services EU-West Outage
CircleCI Database Performance Issue
Microsoft Azure Storage Service Interruption
And finally, here’s some good reads if you’re interested in improving your postmortem skills:
How To Apologize For Server Outages
System Down! An Application Outage Survival Guide
Documenting an outage for a post-mortem review
Blameless PostMortems and a Just Culture
The Three Ingredients of a Great Postmortem