Several services on AWS became degraded and broke a ton of stuff on the net last night. We survived, but our static assets are hosted on S3 and served straight out of US-STANDARD — so there were some problems.
Original incident: http://status.status.io/pages/incident/51f6f2088643809b7200000d/55c8514ff3bc431d5c000643
What happened:
The first alarm came via PagerDuty from a Pingdom transaction check, which indicated that a test login failed.
Immediately we realized that the static resources (images, scripts) hosted on Amazon S3 were sporadically failing to load. A quick manual test of the S3 connection confirmed it was broken.
The AWS status page still didn’t report any issues. Before digging any further, we scanned the interwebs and found a new thread on Hacker News. And someone even referenced a planned maintenance that correlated with the timing.
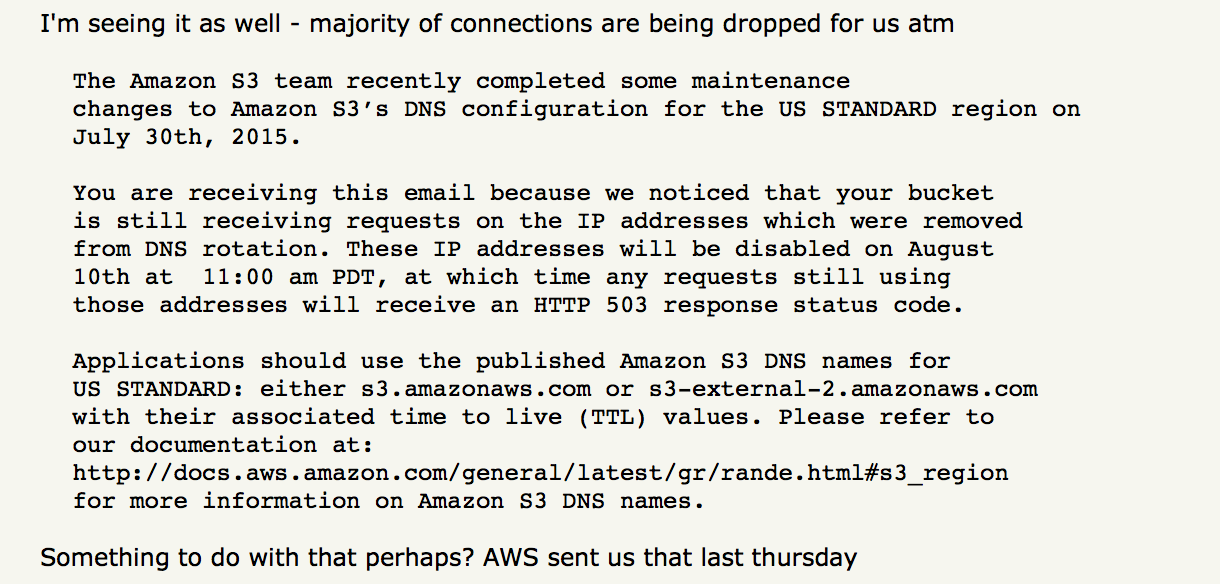
Just as we were ready to contact AWS, the status page was updated to indicate that they were investigating the issue. S3 was fully operational within about four hours.

Impact:
- Degraded user experience due to randomly missing images, scripts or styles
- Slow page loads
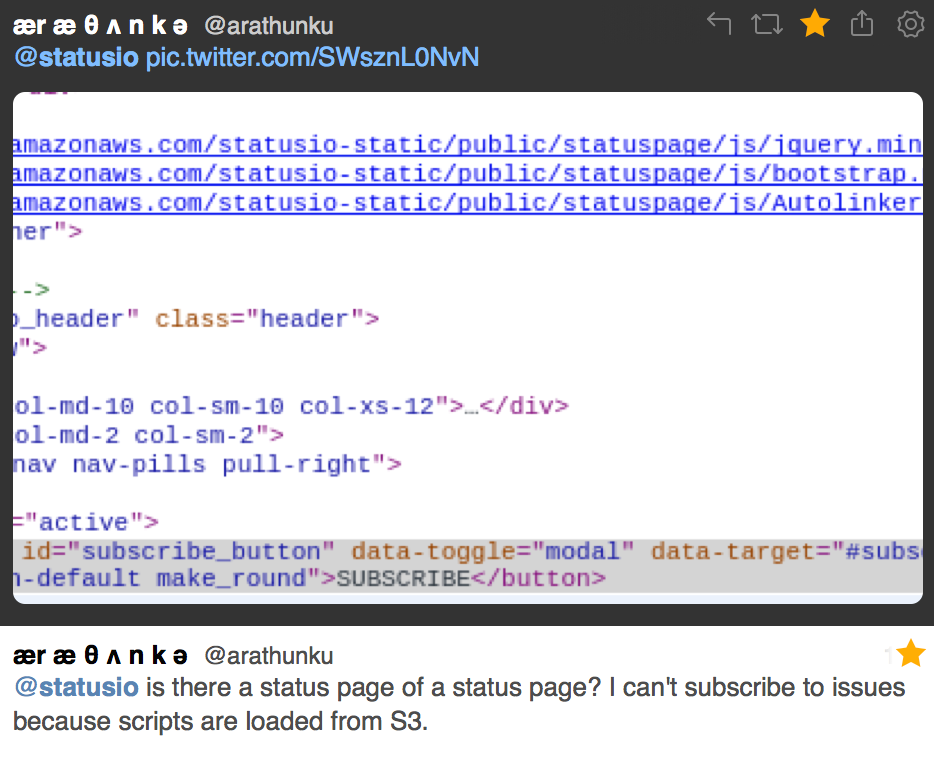
- Broken subscription modal (we were rightfully called out on this one)
Next steps:
Our static assets already reside on S3 in multiple regions. However the bucket name is loaded via a config file that would require a code deployment, and performing deployments is not something we desire to do when AWS is in an unstable state.
We learned that we must be able to change the location of our static assets with the flip of a switch in production. Ideally we would use DNS to handle this change automatically.
In addition, we’re planning to expand our CDN providers and also support serving the assets from our own cache.